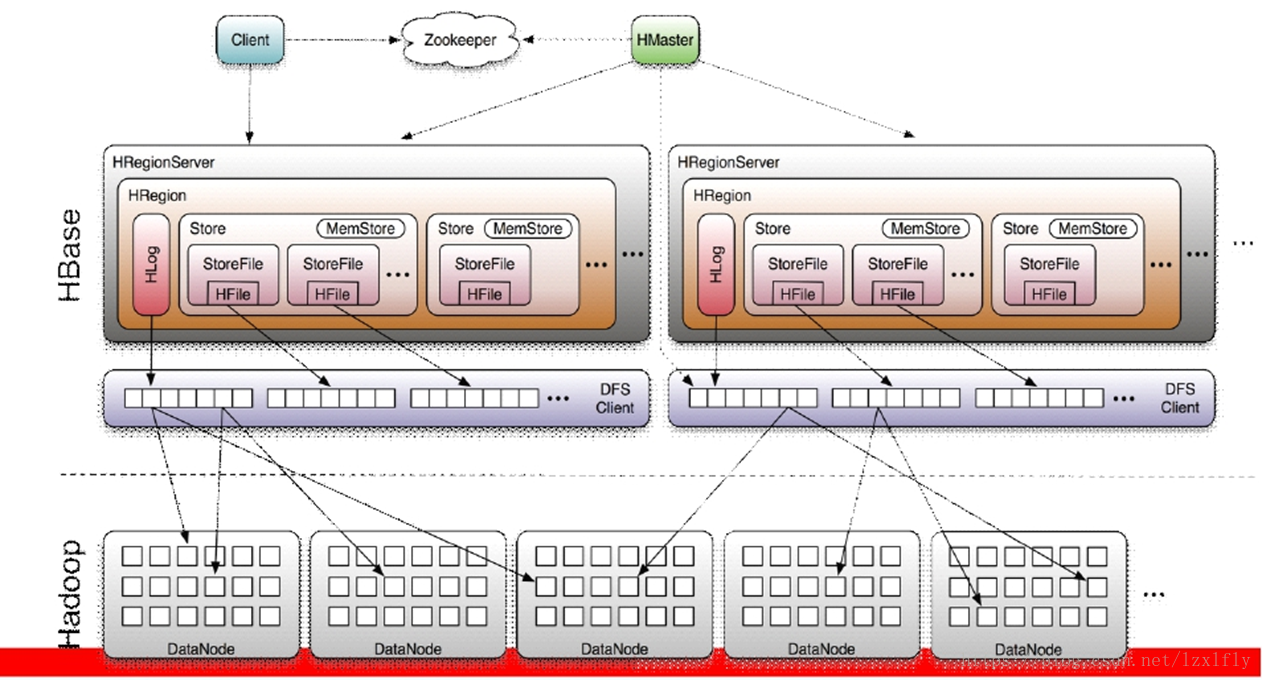
Hbase数据模型与存储结构 一、Hbase简介 Hbase是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库。依托Hadoop-HDFS作为其文件存储系统,利用MapReduce来处理海量数据,用Zookeeper作为其分布式协同服务,主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)。 二、 Hbase数据模型 1、存储模型分布 下边表示了一行,三列的数据,CF1、CF2、CF3是三个不同的列族,在t2时刻CF1下存入列名为q1,值为v1,rowkey为11248112;在t6时刻…

HBase学习之六: hbase的预分区设计 背景:HBase默认建表时有一个region,这个region的rowkey是没有边界的,即没有startkey和endkey,在数据写入时,所有数据都会写入这个默认的region,随着数据量的不断 增加,此region已经不能承受不断增长的数据量,会进行split,分成2个region。在此过程中,会产生两个问题:1.数据往一个region上写,会有写热点问题。2.region split会消耗宝贵的集群I/O资源。基于此我们可以控制在建表的时候,创建多个空regi…
hbase安装配置(整合到hadoop) 如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. 快速单击安装 在单机安装Hbase的方法。会引导你通过shell创建一个表,插入一行,然后删除它,最后停止Hbase。只要10分钟就可以完成以下的操作。 1.1下载解压最新版本 选择一个 Apache 下载镜像:http://www.apache.org/dyn/closer.cgi/hbase/,下载 HBase…

HBase学习之二: hbase分页查询 在hbase中可以使用scan做一些简单的查询,但是要实现多条件复杂查询还需要借助filter(过滤器)来完成,甚至还可以自定义filter实现个性化的需求,项目中需要分页查询,记录了其中的核心代码,以便于查阅。 zookeeper.properties配置文件内容: hbase_zookeeper_quorum=xxx.com,xxx.com,xxx.com zookeeper_znode_parent=/hbase zookeeper集群配置,一般hbase…
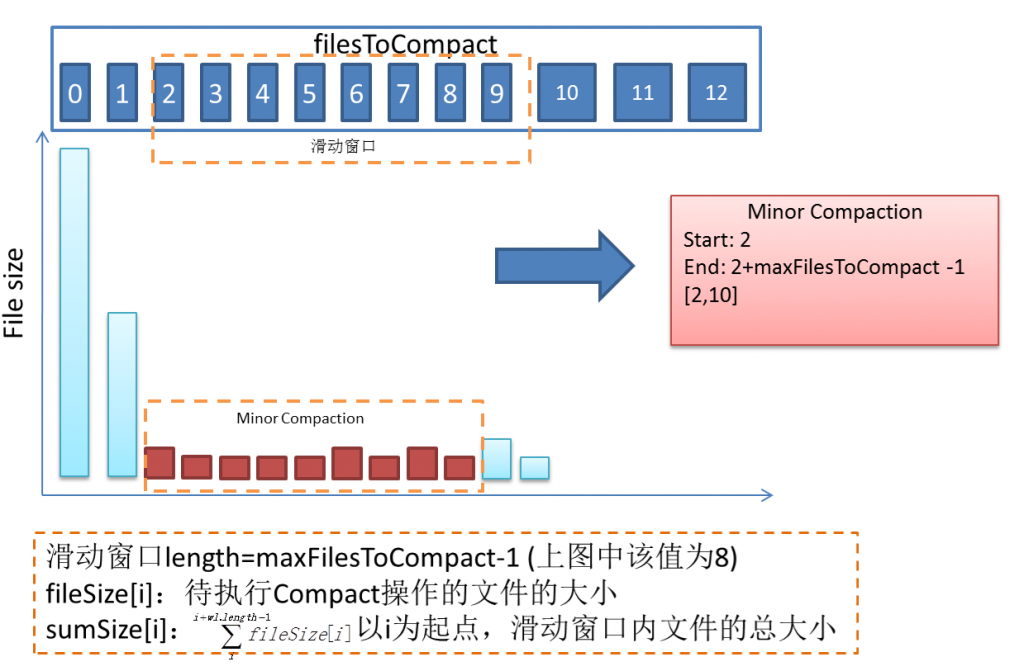
RegionServer维护Master分配给它的region,处理对这些region的IO请求,负责切分在运行过程中变得过大的region, 由于集群性能( 分配的内存和磁盘是有限的 )有限的,那么HBase单个RegionServer的region数目肯定是有上限的
-

- 关注“Harry技术”
-

- 加我微信
